Welcome to the HDRUK Avoidable Admissions Collaboration Docs
This is a the web-guide to help facilitate federated data engineering across each site.
- CI Site: Sheffield
Site Main Sections
index- This navigation pagedocumentation- Partial documentation for the project. Please see the main Sheffield protocol for further details. The aim of this documentation is to encourage co-developmentdata_models- Contains the core data model for the projectguides- How to guides taking beginners through the process of setting up and running the pipeline.code- Explains the code modules for the project for those who want more details.
Common Analytic Approach
To facilitate successful working across all involved sites a common approach needs to be taken. This has been well described as below in the following diagram:
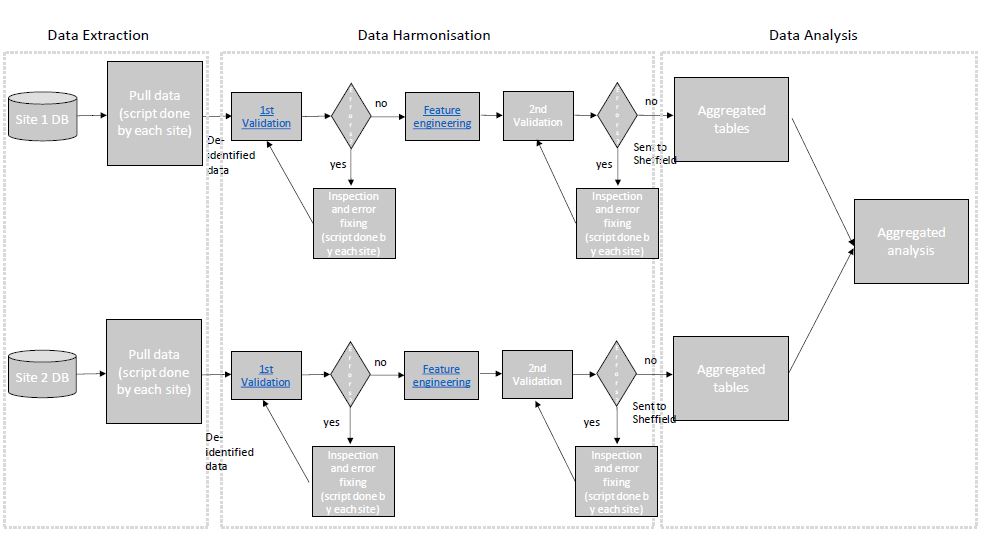
As you can see in the diagram there are 3 major steps to the process which are:
- Data Extraction
- Data Harmonization
- Data Analysis
This repository is therefore laid out in those three steps to keep things simple and easy to follow.
How to Use
We have used python to build this however we have designed it so that you can start with zero knowledge of python and still have it work for you.
In order to reduce complexity the repository has been stripped back to bare bones essentials starting with the installation of python itself within a trust / Uni environment through to running each component. We will keep working to improve it so if something is not right let us know and we will fix it.
The intent is to provide a supportive structure for newcomers while also providing enough flexibility for experienced hands. Each site can embellish the base template as they wish - as long as the core data model and validation, analytics steps are used the output should be at least somewhat standardised.
Repository Layout
The code and documentation in this repository is laid out in three sections corresponding to the three steps laid out as above:
├── mkdocs.yml <- The configuration file for these docs (only necessary for docs development)
├── pipefile and lock <- alternative environment setup (only necessary for docs development)
├── licence <- Project Licence - MIT (Permissive)
├── .pre-commit-config.yaml <- Pre-commit hooks to prevent metadata retention inside notebooks during commits
├── environment.yml <- Environment setup file
├── init.sh and bat <- Setup scripts for windows and linux shells / command line
├── setup.py <- Sets up the python packages
├── README.md <- Taken from https://github.com/LTHTR-DST/hdruk_avoidable_admissions/blob/dev/README.md and simplified. Thanks to vvcb and the LTHRT team for all their work on this!
│
├── docs/
│ ├── index.md <- The index page
│ ├── documentation <- A brief explanation of the project - consult the main protocol for more details
│ ├── data_models <- The data model specs for the project
│ ├── how-to-guides <- How to Guides including starting from scratch
│ ├── code.md <- Codeshares and docstrings
│
├── data_extraction/
│ ├── synthetic_data <- Dummy data for testing (please note the dataset provided is incomplete and provided for demonstation of only a part of the process to get started)
│ ├── extraction.ipynb <- Simple example of extraction process and cleaning with python
│
├── data_harmonization/
│ ├── synthetic_data <- Dummy data for testing - will be generated by data_extraction phase (please note the dataset provided is incomplete and provided for demotion of only a part of the process to get you started)
│ ├── harmonization.ipynb <- Simple example of data harmonization with python
│
├── data_analysis/
│ ├── synthetic_data <- Dummy data for testing - will be generated by data_harmonization phase (please note the dataset provided is incomplete and provided for onstation of only a part of the process to get you started)
│ ├── harmonization.ipynb <- Simple example of data harmonization with python
│ ├── outputs/ <- Output folder for final aggregated results
├── modules/ <- Modules mostly for data harmonization
Please get in contact if you are struggling with anything as you are likely not on your own and will help others by raising any issues.