Step 4) From Extraction to Feature Engineering (Part1 Harmonization)
Data Harmonization
If we reference our initial project data schema we can see the stages needed to perform harmonization:
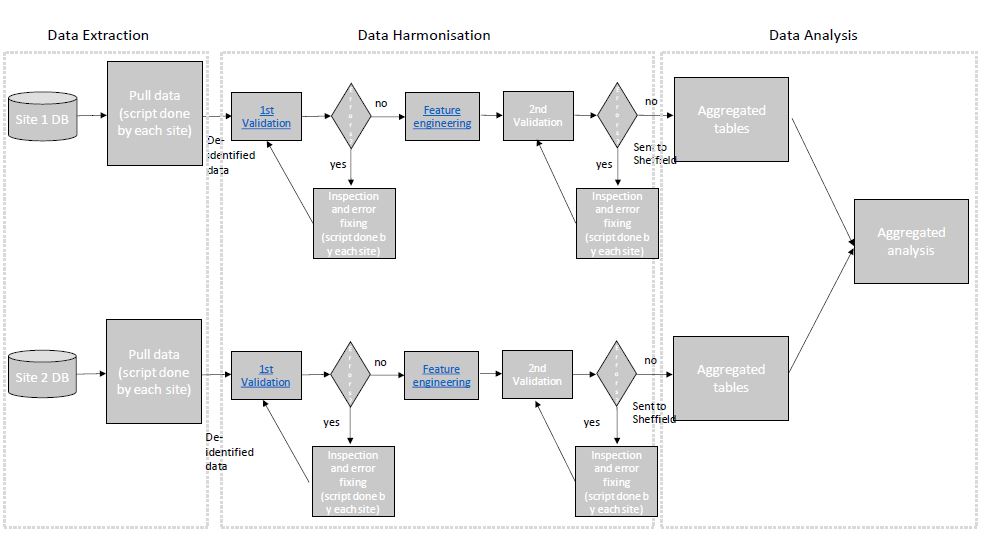
We attempted in the last round to try a validation and it failed. For the purposes of demonstrating what a good synthetic dataset would look like we are going to start by loading this in and validating it as we did last time.
New Dataset
We have now gone back to obtain a new dataset (hopefully this won't have to happen too many times for each site). Unfortunately it is typically required thus why pipelines are so important in these types of projects to minimise project overhead.
Let's load the data in (new dataset):
df = pd.read_csv("synthetic_data/sdv_hdruk_admitted_care_synthetic_data.csv")
First Validation
This time we have ajusted our SQL / python / R code and the data is looking much better so lets try to validate it.
Excellent. This time we have had at least partial success with our new extract.
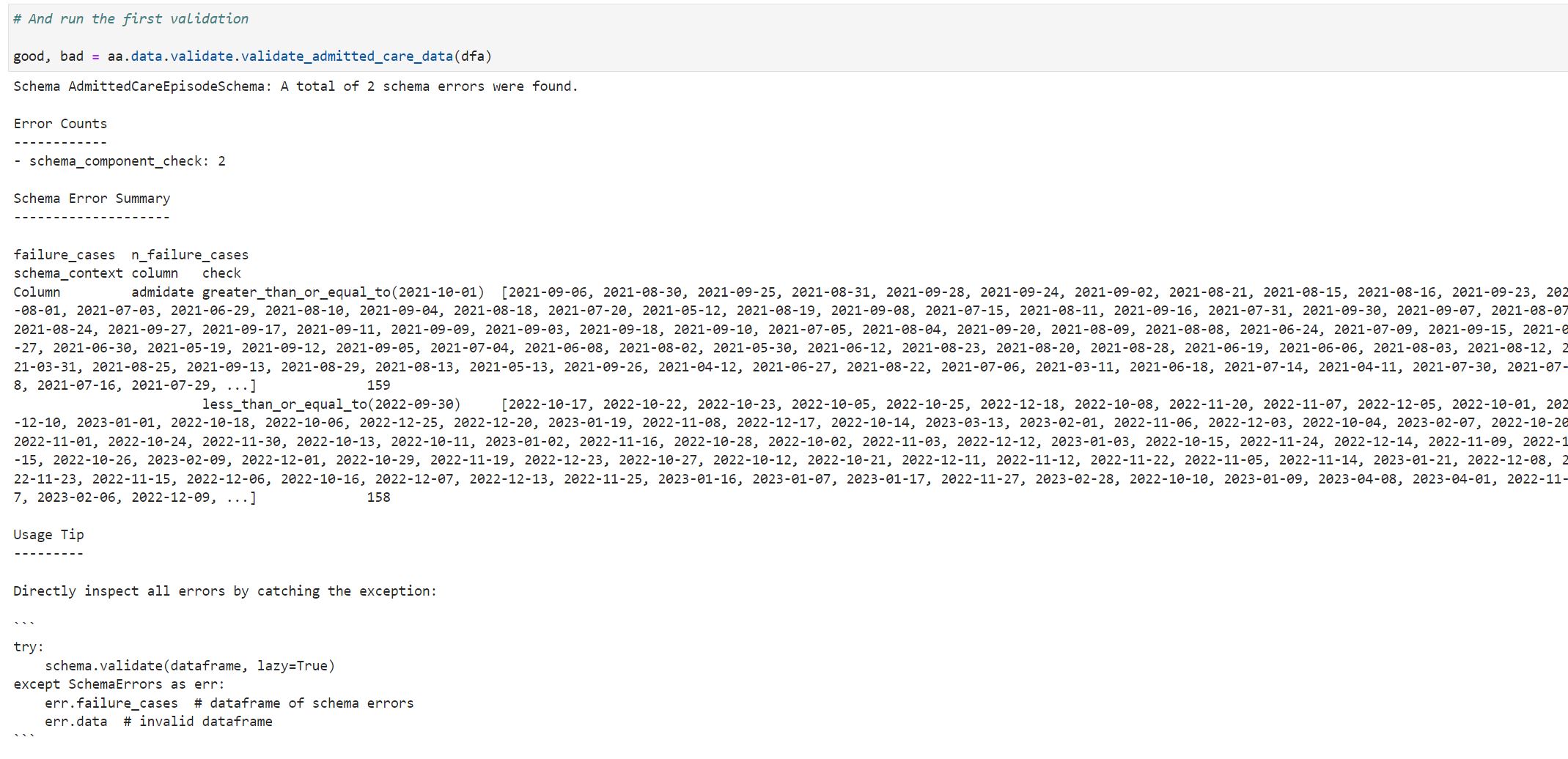
And this time our validations are partially successful but we are still getting some failures

Lets inspect those failures - called 'bad' in this example:
bad[["schema_context", "column", "check", "check_number", "failure_case", "index"]]
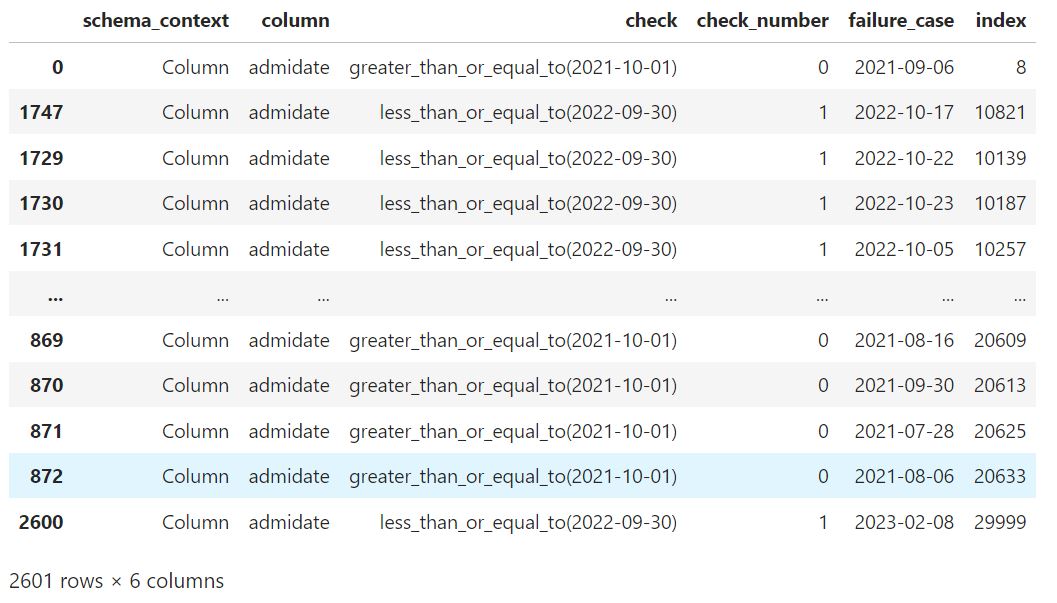
We can see that the dates are out - thus why these failed.
Feature Engineering
We need to perform feature engineering as per the protocol to check our work and ensure everything matches. This can potentially be done in a single line
dfa_features = aa.features.build_features.build_admitted_care_features(good.copy())
Pandas Profiling
We are now in a position to try and visualise our synthetic admissions data to see visually how high quality the data is. We can do this with the pandas profiling package which we have loaded into the ipython notebook. We can see that because this data is synthetic most of the variables cluster around a normal distribution - some of this is legitimate but some of it is not.
It gives us a good idea therefore how high quality the data will be going into the next stage. We will next need to harmonize the ED data however.